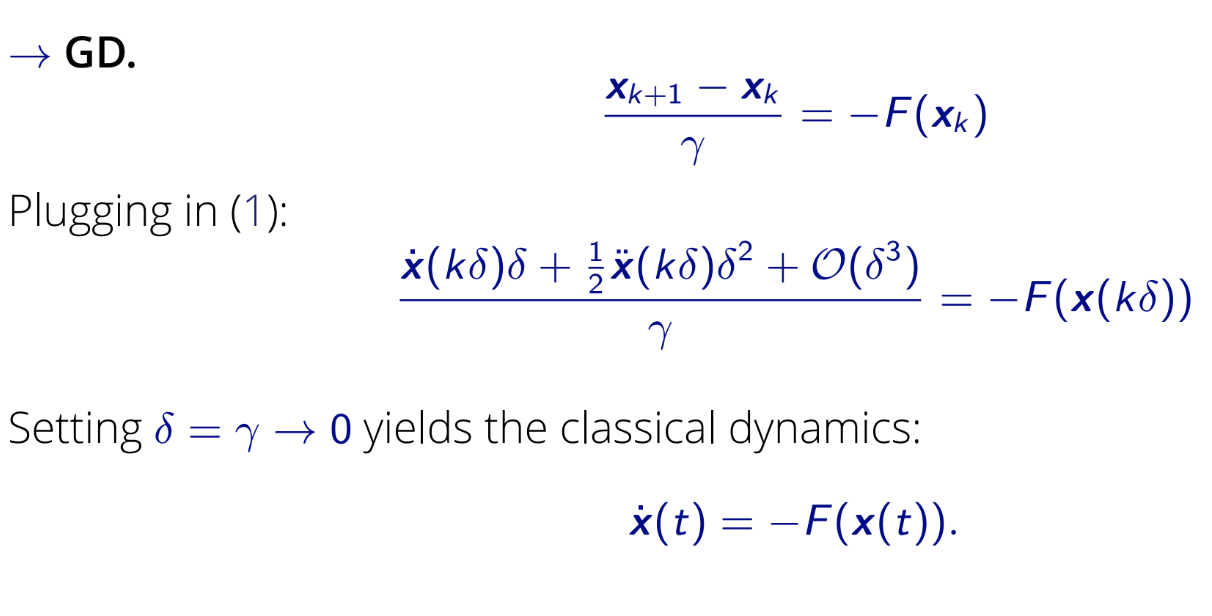
High-Resolution ODEs
From discrete optimization methods to continuous time dynamics, using varying modeling precision.
Hello, I’m Tatjana (/tatiana/). I'm an Assistant Professor at TU Wien in Vienna, Austria. My research focuses on learning dynamics in multi-agent and game-theoretic settings. I enjoy collaborating with students and colleagues on problems at the intersection of optimization, game theory, and machine learning, and I love uncovering simple insights in complex systems. Prior to joining TU Wien, I was a Visiting Professor at Politecnico di Milano (PoliMi), DEIB, where I collaborated with Nicola Gatti and Nicolò Cesa-Bianchi. I hold a Ph.D. from EPFL, and Idiap, advised by François Fleuret. During my doctoral studies, I interned at (i) Mila with Yoshua Bengio and Simon Lacoste-Julien, and at (ii) DeepMind under Irina Jurenka (Higgins). After my Ph.D., I was a Postdoctoral Researcher at EPFL’s MLO Lab with Martin Jaggi, and later at UC Berkeley EECS with Michael Jordan.
» Hiring interns, PhD and Postdocs --> application form. » The Games in ML '26 course materials are available here.
» More broadly, I’m interested in how game-like interactions shape intelligence — not only in AI systems, but also in human cognition and society. (For fun, I recommend Kelly Clancy's talk on how games shape our world!)
June, 2026: A recent TU Wien Informatics post, prepared by Sophie Wiesinger, offers a little more context on my research interests and the motivations behind them. March-July, 2026: More games please! :) We're hosting an ICML workshop on New Frontiers in Game-Theoretic Learning -- NExT-Game. Submission deadline: April 24th AoE. See you in South Korea! March, 2026: I’m teaching a MSc-level course on Games in Machine Learning at TU Wien, starting in March. Course materials available here. Jan., 2026: I was elected as the WiML President! Excited to what comes next! ;) Jan., 2026: I was awarded a VRG grant from the Vienna Science and Technology Fund (WWTF), and I will be joining TU Wien as an Assistant Professor. If you’re interested in joining my group (and living in Vienna!), you can apply here. second-half, 2025: Dynamical systems tools for ML are in vogue! We're hosting a NeurIPS workshop on Dynamics at the Frontiers of Optimization, Sampling, and Games (DynaFront). I'm also excited for the special 20th anniversary edition of the WiML workshop -- stay tuned for announcements. See you in San Diego! July, 2025: I'll be at ICML! We’ll be presenting work on game-theoretic federated learning, where agents operate without full knowledge of others' strategies. We're also organizing the WiML workshop/symposium on Wednesday and co-hosting a social event on Thursday. Looking forward to seeing you in Vancouver! May, 2025: I’m teaching a PhD-level course on Games in Machine Learning at PoliMi, starting in late May. Course materials are available here!
🏅 Thanks to the Vienna Science and Technology Fund (WWTF) for supporting my research, through the generous VRG grant on Multi-Player Artificial Intelligence (`26) of € 1.8 M. 🏅 Thanks to the Swiss National Science Foundation for supporting my research, through the Early.Postdoc.Mobility (in 2021) and the Postdoc.Mobility (in 2023) fellowships.
@article{messina2026learning,
title = {Learning to Diffuse: Mechanism Design in Social Networks with Information Propagation Costs},
author = {Sebastiano Messina and Tatjana Chavdarova},
journal = {New Frontiers in Game-Theoretic Learning - NExT-Game},
year = {2026},
url = {https://openreview.net/forum?id=YORmPd1hO2}
}
@article{praolini2026,
title = {Equilibrium Structure of High-Resolution Differential Equations for Min–Max Optimization},
author = {Federico Praolini and Tatjana Chavdarova},
journal = {Workshop on AI for Mechanism Design and Strategic Decision Making, held at ICLR},
year = {2026},
}
@inproceedings{sanyal2026freq,
title = {Frequency-Based Hyperparameter Selection in Games},
author = {Aniket Sanyal and Baraah A. M. Sidahmed and Rebekka Burkholz and Tatjana Chavdarova},
booktitle = {AISTATS},
year = {2026},
}
@article{foscari2025invisiblehandshake,
title = {The Invisible Handshake: Tacit Collusion between Adaptive Market Agents},
author = {Luigi Foscari and Emanuele Guidotti and Nicolò Cesa-Bianchi and Tatjana Chavdarova and Alfio Ferrara},
journal = {ArXiv:2510.15995},
year = {2025},
}
@article{sanyal2025,
title = {Understanding Lookahead Dynamics Through Laplace Transform},
author = {Aniket Sanyal and Tatjana Chavdarova},
journal = {ArXiv:2506.13712},
year = {2025},
}
@inproceedings{zindari2025decoupled,
title = {Decoupled SGDA for Games with Intermittent Strategy Communication},
author = {Ali Zindari and Parham Yazdkhasti and Anton Rodomanov and Tatjana Chavdarova and Sebastian U Stich},
booktitle = {ICML},
year = {2025},
}
@article{zhao2024learningvariationalinequalities,
title = {Learning Variational Inequalities from Data: Fast Generalization Rates under Strong Monotonicity},
author = {Eric Zhao and Tatjana Chavdarova and Michael I. Jordan},
journal = {ArXiv:2410.20649},
year = {2024},
}
@article{sidahmed2024vimarl,
title = {Variational Inequality Methods for Multi-Agent Reinforcement Learning: Performance and Stability Gains},
author = {Baraah A. M. Sidahmed and Tatjana Chavdarova},
journal = {ArXiv:2410.07976},
year = {2024},
}
@article{alomar2024hypomonotone,
title = {On the Hypomonotone Class of Variational Inequalities},
author = {Khaled Alomar and Tatjana Chavdarova},
journal = {ArXiv:2410.09182},
year = {2024},
}
@article{zindari2024decoupled,
title = {Decoupled Stochastic Gradient Descent for N-Player Games},
author = {Ali Zindari and Parham Yazdkhasti and Tatjana Chavdarova and Sebastian U Stich},
journal = {ICML 2024 Workshop: Aligning Reinforcement Learning Experimentalists and Theorists},
year = {2024},
}
@inproceedings{chavdarova2024acvi,
title = {A Primal-dual Approach for Solving Variational Inequalities with General-form Constraints},
author = {Chavdarova, Tatjana and Yang, Tong and Pagliardini, Matteo and Jordan, Michael I.},
booktitle = {ICLR},
year = {2024},
}
@article{chavdarova2023hrdes,
title = {Last-Iterate Convergence of Saddle Point Optimizers via High-Resolution Differential Equations},
author = {Tatjana Chavdarova and Michael I. Jordan and Manolis Zampetakis},
journal = {Minimax Theory and its Applications},
year = {2023},
}
@inproceedings{yang2023acvi,
title = {Solving Constrained Variational Inequalities via a First-order Interior Point-based Method},
author = {Tong Yang and Michael I. Jordan and Tatjana Chavdarova},
booktitle = {ICLR},
url={https://openreview.net/forum?id=RQY2AXFMRiu},
year = {2023},
}
@article{chavdarova2022contVIs,
title = {Continuous-time Analysis for Variational Inequalities: An Overview and Desiderata},
author = {Tatjana Chavdarova and Ya-Ping Hsieh and Michael I. Jordan},
booktitle= {ICML Workshop on Continuous time methods for Machine Learning},
year = {2022},
}
@article{liu2021peril,
title = {The Peril of Popular Deep Learning Uncertainty Estimation Methods},
author = {Yehao Liu and Matteo Pagliardini and Tatjana Chavdarova and Sebastian U. Stich},
journal = {NeurIPS Workshop on Bayesian Deep Learning},
year = {2021},
}
@article{ManunzaPagliardini2021,
title = {Improved Adversarial Robustness via Uncertainty Targeted Attacks},
author = {Gilberto Manunza and Matteo Pagliardini and Martin Jaggi and Tatjana Chavdarova},
journal = {ICML Workshop on Uncertainty and Robustness in Deep Learning},
year = {2021},
url = {http://www.gatsby.ucl.ac.uk/~balaji/udl2021/accepted-papers/UDL2021-paper-096.pdf}
}
@InProceedings{Yuksel_2021_ICCV,
author = {Y\"uksel, Oguz Kaan and Stich, Sebastian U. and Jaggi, Martin and Chavdarova, Tatjana},
title = {Semantic Perturbations With Normalizing Flows for Improved Generalization},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {6619-6629}
}
@inproceedings{chavdarova2021lagan,
author = {Tatjana Chavdarova and
Matteo Pagliardini and
Sebastian U. Stich and
Fran{\c{c}}ois Fleuret and
Martin Jaggi},
title = {Taming GANs with Lookahead-Minmax},
booktitle = {{ICLR}},
publisher = {OpenReview.net},
year = {2021}
}
@article{Chavdarova:278463,
title = {Deep Generative Models and Applications},
author = {Chavdarova, Tatjana},
institution = {IEL},
publisher = {EPFL},
address = {Lausanne},
pages = {169},
year = {2020},
url = {http://infoscience.epfl.ch/record/278463},
doi = {10.5075/epfl-thesis-10257},
}
@inproceedings{chavdarova2019,
Author = {Tatjana Chavdarova and Gauthier Gidel and François Fleuret and Simon Lacoste-Julien},
Title = {Reducing Noise in {GAN} Training with Variance Reduced Extragradient},
Booktitle = {{Advances in Neural Information Processing Systems (NeurIPS)}},
Year = {2019},
volume = {32},
publisher = {Curran Associates, Inc.},
}
@inproceedings{chavdarova-fleuret-2018,
author = {Chavdarova, T. and Fleuret, F.},
title = {{SGAN}: An Alternative Training of Generative Adversarial Networks},
booktitle = {CVPR},
year = {2018},
}
@inproceedings{chavdarova-et-al-2018,
author = {Chavdarova, T. and Baqué, P. and Bouquet, S. and Maksai, A. and Jose, C. and Bagautdinov, T. and Lettry, L. and Fua, P. and Van Gool, L. and Fleuret, F.},
title = {{WILDTRACK}: A Multi-camera {HD} Dataset for Dense Unscripted Pedestrian Detection},
booktitle = {CVPR},
year = {2018},
pages = {5030-5039},
}
* Equal contributions.
Intelligence often emerges through interaction and competition. Likewise, advanced AI algorithms often rely on competing learning objectives. Whether through data sampling, environmental interaction, or self-play, agents iteratively adapt their strategies in pursuit of an equilibrium—where the competing objectives are balanced. This talk explores the learning dynamics in multiplayer games, where multiple agents learn and adapt simultaneously. We will examine how these dynamics differ from single-agent optimization, addressing key challenges such as rotational learning dynamics, stochastic noise, and strategic constraints. Drawing on examples from machine learning— including robust optimization, generative adversarial networks, and multi-agent reinforcement learning—the talk will highlight the implications of these dynamics for understanding and designing modern learning systems.
From discrete optimization methods to continuous time dynamics, using varying modeling precision.
Email: tatjana.chavdarova[at]tuwien[dot]ac[dot]at Phone: +43 1 58801-194608
 Office FB 03 02, third floor,
Dekanat der Fakultät für Informatik, TU Wien
Karlsplatz 13, 1040 Wien
Office FB 03 02, third floor,
Dekanat der Fakultät für Informatik, TU Wien
Karlsplatz 13, 1040 Wien
